
I am a third year undergraduate major in Computer Science with a concentration in Statistics at Grinnell College, Iowa, USA. My research interests lie in the field of Human Computer Interaction with Artificial Intelligence. I am interested in researching about bias in AI algorithms, especially racial and gender bias in AI algorithms. For the summer of 2024, I am going to Tufts University in the School of Engineering to work with Dr. Elaine Short at the AABL Lab as part of the Distributed Research Experience for Undergraduates organized by Computing Research Association.
Python, R, Java, C
Git, MongoDB, SQL
Academic Research, Technical Writing
Speaking and Presentation Skills
Mentorship, Leadership, Organization

Research Assistant at Tufts University with Dr. Elaine Short at The Assistive Agent Behavior and Learning Lab in the School of Engineering
Click here
Research Assistant at University of Illinois Urbana-Champaign with Dr. Jodi Schneider at Information Quality Lab in the School of Information Sciences
Click here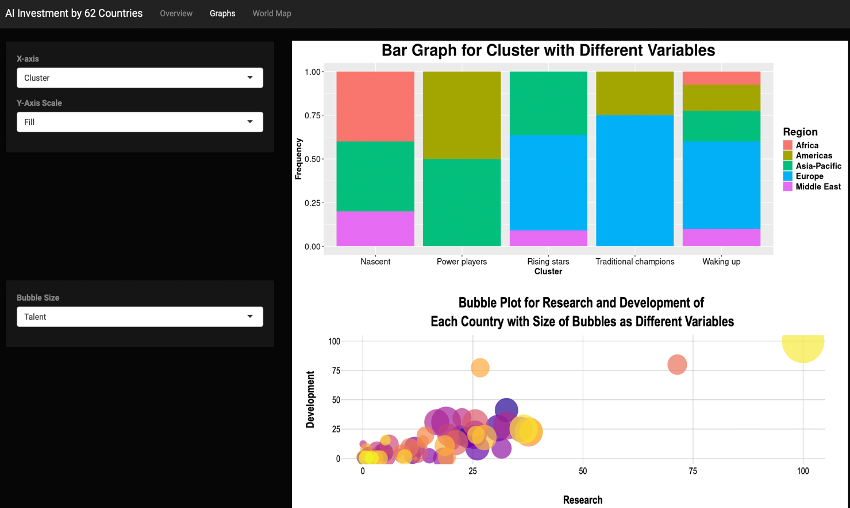
An RShiny app that shows AI investment by 62 countries using various factors such as Research, Development, Income Group, Political Regime, etc. My goal is to create visualizations that would help us look at different factors of a country and their investment in AI to identify more powerful countries.
Click here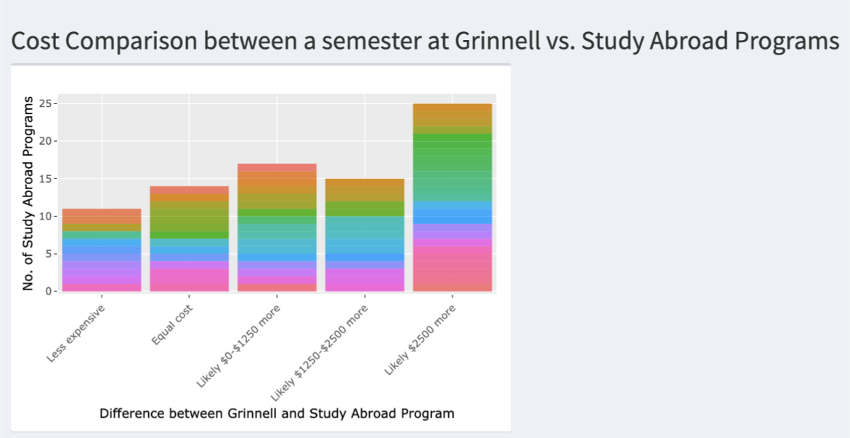
An RShiny app that shows different visualizations for off campus study programs at Grinnell College. It allows users to explore 6 different interactive visualizations that will allow them to interact with a map, filter between bar charts to look at visualizations that filter programs by ethnicity, gender, trip counts, and lastly, a user can compare costs of attending study abroad programs and attending Grinnell College.
Click here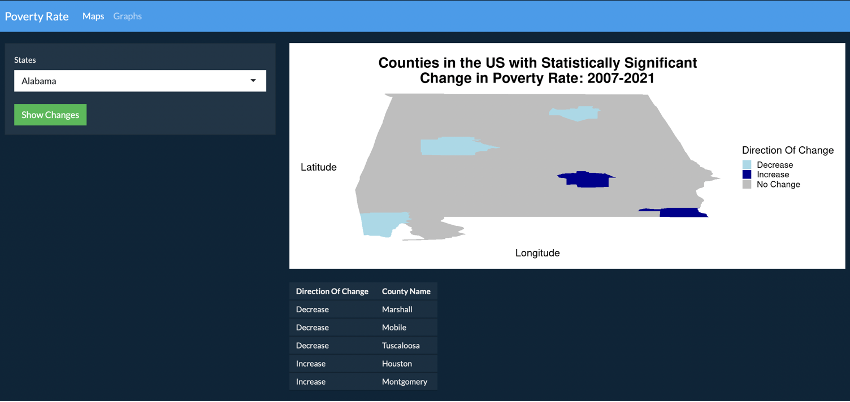
An RShiny app that allows users to look at different US states and their statistically significant changes in poverty rate from the years 2007-2021. The app displays changes in counties state wise and also lets users compare changes in poverty rates in counties for all the states in the USA.
Click here I presented at METSTI 2023: Workshop on Informetric, Scientometric,
and Scientific and Technical Information Research for my Text
Mining Scholarly Publications using APIs.
My extended abstract was selected and you can read it here and my presentation
for the workshop is here .
Sarraf, I., Fu, Y., Schneider, J. (2023, October 27). Text Mining Scholarly Publications using APIs, METSTI 2023: Workshop on Informetric, Scientometric, and Scientific and Technical Information
Research, Association for Information Science and Technology (ASIST). https://doi.org/10.5281/zenodo.10581542